最近在网上搜代码,找到一些不错的源码,作为我的比赛项目的参考。不过看代码的时候发现一个很重要的问题,很多人忽略(包括我经常看的XX的视频,还有我自己)。这个问题虽然小,不过有时候可以要了C/C++程序的命。
在函数的说明文档里,有些时候某个函数的某个参数的说明是这样:
/* Maximum length of zSql in bytes. */
有的函数又是这样写的:
The size of the lpFilename buffer, in TCHARs.
一个in bytes和一个in TCHARS(或in chars),他们有什么区别?其实区别很大,in bytes表示以字节为单位,in tchars表示传入的是数组长度。这又涉及到编码问题。
C/C++里面有宽字符(wchar_t)和窄字符(char)两种字符类型。每个char占1个字节,每个wchar_t占两个类型。tchar是一个通用类型,如果我们在工程设置里打开宽字节,tchar就被解析成wchar_t,否则就被解析成char。
我们写windows程序一般都是用tchar类型作为我们的字符类型。比如定义一个TCHAR szBuf[256];就是一个字符数组。(如果没开启宽字符,则被解析成char szBuf[256],和我们平时写的程序一样)
1.在没开启宽字符(unicode)的时候
因为char只占用1个字节,所以char szBuf[256]占用256个字节,即:
sizeof(szBuf) == 256
_countof(szBuf) == 256 // _countof函数意思是求数组的长度
得到的是一样的结果。
所以in bytes的时候,传入sizeof(szBuf)就行了。比如我在《 sqlite的C语言使用 》讲过的sqlite3_prepare函数,第三个参数就传入sizeof(zSql)。
in CHARs的时候,可以传入_countof(szBuf),也可以直接传入256,。
在没开启uncide的情况下,就算sizeof和_countof用混了,也不影响程序最终运行。因为结果都是256.
2.在开启了宽字节UNICODE的时候
sizeof(szBuf) == 512
_countof(szBuf) == 256
两者不一样了。因为tchar被解析成wchar_t,一个wchar_t占两个字节。如果这时候,函数里用混的话,可能会出现意想不到的结果。
比如大家读这段有问题的代码:
int _tmain(int argc, _TCHAR* argv[])
{
TCHAR strDir[10];
int large = sizeof(strDir);
int re = GetModuleFileName(NULL,strDir,large);
return 0;
}
现在这个GetModuleFileName的用处是获取现在程序运行的目录,得到的信息就保存在strDir里。第三个参数说明就是: The size of the lpFilename buffer, in TCHARs. 应该传入_countof(strDir)可是我们现在传入的是sizeof(strDir),传成了字符数组占用空间的大小。调试运行看:
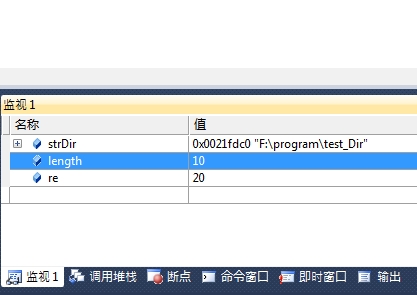
明明定义的strDir是strDir[10],却装了超过10的数据"F:\program\test_Dir",明显溢出了。
在一般情况下,这样的溢出不会造成程序崩溃,但如果正好有程序需要用溢出的这块地方的内存,本程序就崩溃了。
所以我建议大家,在使用此类含有字符串数组长度的函数时,看清楚说明文档中的说明,到底是要传入它的大小还是它的长度。比如这类函数:strcpy_s,strcat_s,wcscpy_s..这种字符串操作的函数都是传入字符串的长度,也就是_countof,以后一定不要错了。
多说一句,一般MSDN里,没有特别说是in bytes的(比如说什么Size of the destination string buffer),一般都是要传入字符串长度。
